

2 May 2025
A Breakdown of OpenAI, Anthropic, Google, Grok, Groq, AWS and Cerebras Models Thus Far Available in PowerFlow
The University of Nicosia is proud to offer faculty and staff access to some of the most powerful AI models available today through its advanced Powerflow tool.

Below is a concise summary of the five strongest models across OpenAI, Anthropic, Google, Groq, Grok, Amazon Bedrock and Cerebras selected for their intelligence, performance, and versatility. Task requirements should guide your choice: for complex reasoning and research workflows, opt for the most powerful models; for routine daily tasks—such as summarization or email drafting—a faster, more cost-efficient model is often preferable.
Most Powerful
| Model Name | Company | Context Window | Price (Approx.) | Key Strengths |
|---|---|---|---|---|
| GPT-5.4 Pro | OpenAI | 1M tokens | Input: 30.00; Output: 180.00 | The smartest and most precise model. Uses extended compute to think harder and deliver consistently better answers on the toughest problems. |
| GPT-5.4 | OpenAI | 1M tokens | Input: 2.50; Output: 15.00 | OpenAI's latest frontier model with state-of-the-art coding, and the most token-efficient reasoning yet. |
| Claude 4.6 Opus | Anthropic | 1M tokens | Input: 5.00; Output: 25.00 | Low-hallucination, tool-centric agents and long-running coding with traceable plans. First Opus-class model with 1M token context. Strongest Claude on coding and agentic execution; premium pricing. |
| Gemini 3.1 Pro Preview | 1M tokens | Input: 2.00; Output: 12.00 | Excels in reasoning, coding, and multimodal tasks; Google's most capable public model. |
Most Efficient for daily use
| Model Name | Company | Context Window | Price (Approx.) | Key Strengths |
|---|---|---|---|---|
| GPT-5.4 Mini | OpenAI | 400k tokens | Input: 0.75; Output: 4.50 | Fastest model, with extremely low cost per token, and strong reasoning for its size. |
| Grok 4.1 Fast Reasoning | xAI | 2M tokens | Input: 0.20; Output: 0.50 | Optimized for speed and efficiency with the industry's largest context window; suitable for applications requiring quick, logical responses with lower computational costs. |
| GPT-5.4 Nano | OpenAI | 400k tokens | Input: 0.20; Output: 1.25 | Ultra-cheap for classification, routing, and concise summaries at scale. Ideal for high-QPS endpoints and autocomplete. |
Using the Recommended Models List
To streamline your workflow, Powerflow features a 'Recommended' section at the top of the model selector, divided into:
- Smart: The most powerful models for complex reasoning, research, and advanced coding (GPT-5.4 (High), GPT-5.4 Pro Claude Opus 4.6, Gemini 3.1 Pro Preview)
- Fast: The most efficient models for daily tasks, offering speed and cost-effectiveness (GPT-5.4 (Medium), GPT-5.4 Nano, Grok 4.1 Fast Reasoning)
These recommendations align with the detailed breakdowns below, helping you quickly choose between maximum capability and optimal efficiency.
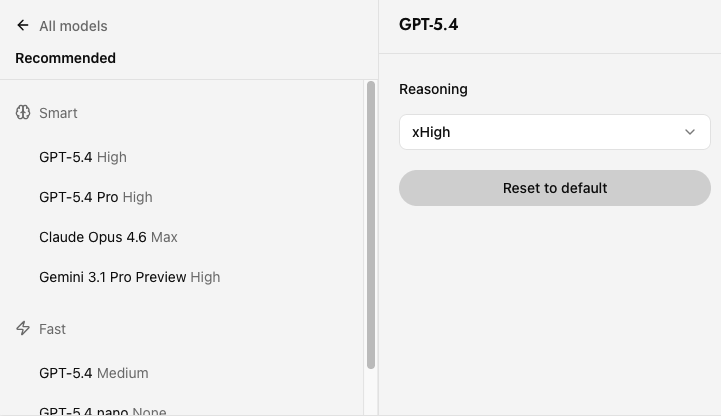
This section provides a detailed evaluation of the leading AI offerings from OpenAI, Anthropic, Google, and other major providers. Each model is analyzed in terms of its context capacity, cost efficiency, and benchmark performance, helping you select the optimal tool for your specific workflow needs. Continuous updates ensure you’re always working with the latest capabilities and pricing information.
OpenAI
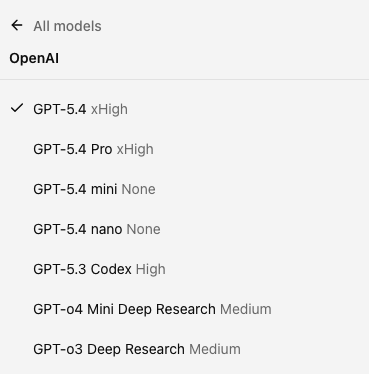
| Model Name | Context Window | Cost (USD per 1M tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| GPT-5.4 | 1M tokens | Input: 2.50; Output: 15.00 | OpenAI's latest frontier model with native computer-use capabilities. Best for complex professional work, agentic workflows (tools/search/code), whole-repo coding, enterprise-grade research synthesis, and handling very long specs and multi-file edits. First general-purpose model able to operate across software from screenshots. | 75% on OSWorld (human: 72.4%); 57.7% on SWE-bench Pro; 33% fewer factual errors vs GPT-5.2; supports 1M context via Codex (272K standard, extendable). |
| GPT-5.4 Pro | 1M tokens | Input: 30.00; Output: 180.00 | Highest-fidelity GPT-5.4 variant optimized for accuracy, complex problem-solving, extended reasoning tasks, advanced coding workflows, multi-step planning, healthcare analysis, financial modeling | GPT-5.4 Pro uses extended compute with higher reasoning budget per request. Supports reasoning.effort: medium, high, xhigh. Sets new state of the art of 89.3% on BrowseComp. Some requests may take several minutes to finish. |
| GPT-5.4 Mini | 400k tokens | Input: 0.75; Output: 4.50 | Fast, cheaper GPT-5.4 for production agents/coding that need accuracy without full GPT-5.4 cost; good for diffs, batch edits, and long context. | Shares GPT-5.4's coding gains; significantly improved over GPT-5 Mini across coding, reasoning, multimodal understanding, and tool use. 400k context window with 128k max output tokens. |
| GPT-5.4 Nano | 400K tokens | Input: 0.20; Output: 1.25 | Ultra-cheap/fast for classification, data extraction, ranking, routing, summaries, autocomplete; ideal brain for high-QPS endpoints and as a fast sub-agent in multi-model architectures. | GPT-5.4 reasoning at lowest cost tier; ideal for high-QPS endpoints and autocomplete. |
| GPT-5.3 Codex | 400k tokens | Input: 1.75; Output: 14.00 | Specialized for code generation, building projects, feature development, debugging, large-scale refactoring, and code review. Optimized for coding agents and produces cleaner, higher-quality code outputs. | Predecessor to GPT-5.4; strong code output quality; optimized specifically for coding workflows. |
| GPT-o4 Mini Deep Research | 200k tokens | Input: 1.10; Output: 4.40 | A lighter, faster Deep Research model for continuous knowledge discovery, summarization, and daily intelligence gathering. Optimized for cost-efficient retrieval and sustained context handling. | Smaller, faster Deep Research variant built on o4-mini. Optimized for cost-efficient retrieval and sustained context handling across extended research sessions. |
| GPT-o3 Deep Research | 200k tokens | Input: 10.00; Output: 40.00 | Purpose-built for long-form analytical reasoning, scientific exploration, and cross-document synthesis. Ideal for academic, legal, and technical research where depth and accuracy outweigh speed. | Purpose-built for long-form analytical reasoning. Combines o3’s deep scientific reasoning capabilities with web browsing and cross-document synthesis for comprehensive research tasks. |
- Use GPT-5.4 pro when you truly need the longest, most careful “think hard” reasoning (it replaces o3-pro for that role).
- Pick GPT-5.4 for cost-efficient reasoning at scale (math/coding/vision) and high-throughput workloads.
- Use GPT-5.4 nano for the cheapest, fastest routing, tagging, and brief summaries (swap out 4.1 nano unless you need its specific behavior).
- Use GPT-5.3 Codex when you need a dedicated coding agent for building projects, debugging and large-scale refactoring.
Deep Research Models
- GPT-o3 Deep Research – Purpose-built for long-form analytical reasoning, scientific exploration, and cross-document synthesis. Ideal for academic, legal, and technical research where depth and accuracy outweigh speed.
- GPT-o4 Mini Deep Research – A lighter, faster Deep Research model for continuous knowledge discovery, summarization, and daily intelligence gathering. Optimized for cost-efficient retrieval and sustained context handling.
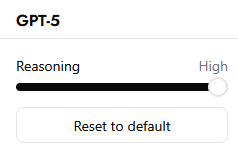
-
low: Maximizes speed and conserves tokens, but produces less comprehensive reasoning.
-
medium: The default, providing a balance between speed and reasoning accuracy.
-
high: Focuses on the most thorough line of reasoning, at the cost of extra tokens and slower responses.
- xhigh: Maximum reasoning effort, designed for complex tasks
Anthropic

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| Claude Opus 4.6 | 1M tokens | Input: 5.00; Output: 25.00 | Best for low-hallucination, tool-centric agents and long-running coding workflows: multi-repo refactors, governed JSON/function calls, retrieval-grounded analysis, and day-long autonomous runs with traceable plans. First Opus-class model with 1M token context. Plans more carefully, sustains agentic tasks for longer, and has better code review and debugging skills. | Anthropic's highest agentic coding scores; nearly doubles Opus 4.5's ARC AGI 2 result (68.8% vs 37.6%). 78.3% on SWE-bench Verified. 128k output tokens supported. |
| Claude Sonnet 4.6 | 1M tokens | Input: 3.00; Output: 15.00 | Strong general-purpose model for agentic coding, terminal and tool use, deep math reasoning, and realistic computer-use tasks. Near-Opus performance at Sonnet pricing — 5x cheaper than Opus. Ideal for full codebase analysis, lengthy contracts, or dozens of research papers. | 79.6% on SWE-bench Verified and 72.5% on OSWorld — within 1-2 points of Opus 4.6. Math leap from 62% to 89%. 1M token context window at standard $3/$15 pricing. Developers with early access prefer Sonnet 4.6 to its predecessor by a wide margin. |
| Claude Haiku 4.5 | 200K tokens | Input: 1.00; Output: 5.00 | Near-frontier coding and reasoning at a fraction of Sonnet's cost. Ideal fast daily driver for production agents, chat assistants, customer support, coding help, and sub-agent orchestration where speed and price matter. Runs 4-5x faster than Sonnet 4.5. | 73.3% on SWE-bench Verified (highest after Sonnet 4.5, surpassing Sonnet 4). 50.7% on computer-use benchmarks (outperforms Sonnet 4's 42.2%). 89.9 tokens per second output speed. Anthropic's safest model by automated alignment assessment. |
- Claude Opus 4.6: For the absolute best coding, math, and complex reasoning tasks based on new data.
- Claude Sonnet 4.6: Near-Opus performance at a fifth of the cost. Excels in advanced coding, workflows, and full codebase analysis with 1M context.
- Claude 4.5 Haiku: Perfect for quick, cost-conscious tasks like chatbots, summarization, and production agents. Three times cheaper and twice as fast as Sonnet.

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| Gemini 3.1 Pro Preview | 1M tokens | Input: 2.00; Output: 12.00 | Best for complex reasoning, coding, and multimodal tasks (text, audio, images, video, and code). Strong in creative writing, logic-heavy tasks, data synthesis, and explaining complex topics. Google's most capable public model. | Google’s most capable public model. Strong on MMMU-Pro and Humanity’s Last Exam. |
| Gemini 3.1. Flash-Lite Preview | 1M tokens | Input: 0.25; Output: 1.50 | Fast, cost-efficient model with excellent speed metrics. Suitable for real-time summarization, automation, and agent workflows with light multimodal support. | Elo score of 1432 on Arena.ai Leaderboard. Optimized for fast Time to First Answer Token and high output speed. |
| Gemini 3 Pro Image Preview | 66k tokens | Input: 2.00; Output: 12.00 | Optimized for image generation and understanding with high-fidelity visual output alongside text capabilities. | Strong visual understanding and generation capabilities. |
| Gemini 3 Flash Preview | 1M tokens | Input: 0.10; Output: 0.40 | Fast, cost-efficient model for real-time AI interactions, chatbots, and automation. | Intelligence Index score of 35. Optimized for fast-response applications. |
- Gemini 3.1 Pro Preview: best for complex reasoning, creative writing and high-end applications.
- Gemini 3 Flash Preview: ideal for real-time AI interactions, fast automation, high-speed summarization, and cost-effective deployments.
xAI

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| Grok 4.20 Beta | 2M tokens | Input: 2.00; Output: 6.00 | xAI's newest flagship model featuring a native 4-agent collaboration system (Grok, Harper, Benjamin, Lucas) that reasons in parallel and debates internally before delivering a unified response. Industry-leading speed and agentic tool calling. Complex reasoning, real-time search, multi-agent workflows, academic-level tasks. | Lowest hallucination rate on the market with strict prompt adherence. 65% reduction in hallucinations over Grok 4.1. Strong gains in coding, math, and engineering reasoning. ~233 tokens/s output speed (reasoning), ~201 tokens/s (non-reasoning). |
| Grok 4.20 Beta (Non Reasoning) | 2M tokens | Input: 2.00; Output: 6.00 | Same capabilities as Grok 4.2o Beta but skips the thinking-tokens phase for instant, pattern-matched answers. Best for straightforward queries where speed is the priority. | Intelligence Index score of 30 (non-reasoning). Same pricing structure; skips chain-of-thought for faster responses on simpler tasks. |
| Grok 4.1 Fast Reasoning | 2M tokens | Input: 0.20; Output: 0.50 | Optimized for speed and efficiency with the industry's largest context window at 2M tokens. Generates thinking tokens for step-by-step chain-of-thought analysis. Best for complex, multi-step problems needing careful analytical solutions at low cost. | Intelligence Index score of 39 (well above average of 19). 153.6 tokens/s output speed. Halved hallucination rates versus Grok 4 Fast. Native support for web search, X search, and code execution. |
| Grok 4.1 Fast (Non-Reasoning) | 2M tokens | Input: 0.20; Output: 0.50 | Same capabilities as Grok 4.1 Fast Reasoning but without thinking tokens. Ideal for tasks needing fast responses without chain-of-thought overhead. | Same pricing and context as reasoning variant. Skips chain-of-thought for lower latency on straightforward tasks. |
| Grok Code Fast 1 | 256k tokens | Input: 0.20; Output: 1.50 | Specialized coding model optimized for code generation, debugging, and software development tasks. | 64.44 on LiveBench Coding. Optimized for code-specific workloads. |
| Grok 4 Fast Reasoning | 2M tokens | Input: 0.20; Output: 0.50 | Cost-effective reasoning model with deep chain-of-thought analysis. Good for complex multi-step problems needing careful analytical solutions at an ultra-low price point. | Intelligence Index comparable to more expensive models. 120.4 tokens/s output speed. ~40% more token-efficient than prior Grok 4, resulting in a 98% reduction in effective cost for many tasks. |
| Grok 4 Fast (Non-Reasoning) | 2M tokens | Input: 0.20; Output: 0.50 | Same capabilities as Grok 4 Fast Reasoning but skips the thinking-tokens phase for instant, pattern-matched answers. Best for straightforward queries, simple automation, and high-speed chatbot applications where speed is the priority. | Same pricing and context window as reasoning variant. Skips chain-of-thought for lower latency on simpler tasks. Reduced hallucinations and better tool-calling compared to prior Grok models. |
Which Grok model should you use?
- Grok 4.20 Beta: ideal for deep reasoning, research-heavy workflows, complex STEM tasks, and long document understanding.
- Grok 4.1 Fast Reasoning: great for cost-effective automation, quick logic-based tasks, and high-speed chatbot applications.
Groq-Based Models

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| Llama 4 Scout 17B 16E | 128K tokens | Input: 0.11; Output: 0.34 | Natively multimodal model enabling text and image understanding. Ideal for natural assistant-like chat, image recognition, coding tasks, document analysis, and maintaining conversation history. Supports 12 languages. | MoE architecture: 17B active parameters, 109B total, 16 experts. MMLU Pro: 52.2, ChartQA: 88.8, DocVQA: 94.4. ~750 tokens/s on Groq. Supports tool use, JSON mode, and vision. |
| GPT OSS 120B | 128K tokens | Input: 0.15; Output: 0.60 | OpenAI's flagship open-weight MoE model. Designed for high-capability agentic use — matches or surpasses proprietary models like o4-mini on many benchmarks. Ideal for advanced research, autonomous tools, and agentic applications. | MoE architecture: 120B total parameters, 5.1B active per forward pass. 36 layers, 128 experts, Top-4 routing. Matches or exceeds o4-mini on competition coding (Codeforces), MMLU, HLE, tool calling (TauBench), and HealthBench. ~3,000 tokens/s on Cerebras hardware. |
| Qwen 3-32B | 128K tokens | Input: 0.29; Output: 0.59 | Versatile mid-size model for coding, reasoning, and multilingual tasks. | 93.8% on ArenaHard, 81.4% on AIME 2024, 65.7% on LiveCodeBench, 72.9% on AIME 2025, 71.6% on LiveBench. ~400 tokens/s on Groq. Supports tool use, JSON mode, and reasoning. |
| Llama 3.3 70b | 128K tokens | Input: 0.59; Output: 0.79 | Reading lengthy academic papers, detailed Q&A, and moderate coding/logic tasks. | Comparable in context size to other 128K models. Strong general-purpose performance. |
| Llama 3.1 8b | 128K tokens | Input: 0.05; Output: 0.08 | Lightweight tutoring or instruction-based chat. | 128K context window supported by Groq’s Llama 3.1 8B Instant variant. Not suitable for large or highly complex tasks. Best for simple, fast interactions. |
-
Llama 4 Scout 17B 16E: Best for multimodal tasks (text + image), multilingual applications, and when you need strong performance from a lightweight MoE architecture.
-
GPT OSS 120B: Best for agentic use cases requiring frontier-class intelligence at an open-weight price point.
-
Qwen 3-32B: Excellent for reasoning-heavy tasks with seamless thinking/non-thinking mode switching. Strong coding and multilingual support.
-
Llama 3.3 70B: Best for long documents (131k tokens) if you need a moderate level of coding/logic with strong multilingual capabilities.
-
Llama 3.1 8B: Ideal for ultra-cheap, high-speed simple tasks like classification, chatbots, and content filtering.
Amazon Bedrock Models

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| Nova 2 Lite | 1M tokens | Input: 0.30; Output: 2.50 | Cost-effective model for document analysis, summarization, and real-time interactions with large context. | 1M token context at affordable pricing; balanced cost and capability. |
| Nova Pro | 300k tokens | Input: 0.80; Output: 3.20 | Advanced multimodal tasks, including text, image, and video processing; suitable for complex agentic workflows and document analysis. | Achieved competitive performance on key benchmarks, offering a strong balance between cost and capability. Supports model distillation to Lite and Micro variants for optimized deployment. |
| Nova Lite | 300k tokens | Input: 0.06; Output: 0.24 | Real-time interactions, document analysis, and visual question answering; optimized for speed and efficiency. | Faster output speeds and lower latency compared to average. 300k token context window. Great for real-time summarization, translation, and basic visual search. |
| Nova Micro | 128k tokens | Input: 0.035; Output: 0.14 | Text-only tasks such as summarization, translation, and interactive chat; excels in low-latency applications. | Offers the lowest latency responses in the Nova family. ~195 tokens/s output speed. Ideal for high-volume classification, routing, and structured data extraction at minimal cost. |
Which bedrock model should you use?
-
Nova 2 Lite is Amazon's newest reasoning model, offering a 1M token context window with extended thinking capabilities. Best for everyday AI tasks requiring deep analysis, web grounding, and multimodal understanding. The best combination of price, performance, and speed.
-
Nova Pro for advanced multimodal tasks and complex document analysis with strong cost-effectiveness.
-
Nova Lite provides a cost-effective solution for tasks requiring real-time processing and document analysis, with a balance between performance and affordability.
-
Nova Micro is optimized for speed and low-latency applications, making it ideal for tasks like summarization and translation where quick responses are essential.
Cerebras Models

| Model Name | Context Window | Cost (USD per 1M Tokens) | Usefulness (Examples) | Benchmark Notes |
|---|---|---|---|---|
| GLM. 4.7 | 200k tokens | Input: 2.25; Output: 2.75 | Large 355B parameter model delivering frontier-level reasoning at Cerebras inference speeds. Strong for complex analysis and enterprise workloads. | Outperforms open-weight models like DeepSeek-V3.2 on key developer evaluations. Comparable intelligence with leading closed models on coding and agentic workloads. ~1,000 tokens/s on Cerebras (up to 1,700 TPS for some use cases). 355B parameters. |
| Llama 3.1 8B | 128K tokens | Input: 0.10; Output: 0.10 | Lightweight tutoring, instruction-based chat, content filtering, and data analysis. The fastest model on Cerebras for simple tasks. | ~2,200 tokens/s on Cerebras — the fastest inference available. 8B parameters. Ultra-low cost and latency for high-volume, low-complexity applications. |
| Llama 3.3 70B | 128K tokens | Input: 0.85; Output: 1.20 | Reading lengthy academic papers, detailed Q&A, coding assistance, and moderate-complexity reasoning tasks. Good general-purpose open-weight model running at Cerebras speed. | 70B parameters. 131k context window. Strong multilingual capabilities. Supports function calling. Higher cost than smaller models but significantly more capable for complex tasks. |
| GPT-OSS 120b | 128K tokens | Input: 0.35; Output: 0.75 | High reasoning model for on-prem/VPC deployments, agent/tool-heavy apps, and production coding workflows. | Outperforms OpenAI o3-mini and matches or exceeds OpenAI o4-mini on competition coding (Codeforces), general problem solving (MMLU and HLE) and tool calling (TauBench). Strong on health-related queries (HealthBench) and competition mathematics (AIME 2024 & 2025). |
| Qwen 3 32B | 128K tokens | Input: 0.40; Output: 0.80 | Versatile mid-size model with strong coding and reasoning capabilities at competitive pricing. | Intelligence Index score of 59. Competitive performance at a fraction of frontier model cost. |
| Qwen 3 235B Instruct (2507) | 128K tokens | Input: 0.60; Output: 1.20 | Large-scale reasoning model with strong performance across benchmarks. Well-suited for complex analysis and enterprise deployments. | State-of-the-art among non-reasoning open-weight models on the Artificial Analysis Intelligence Index. ~1,400 tokens/s on Cerebras. 235B parameters (MoE, 22B active). Exceptional price-performance for high-intelligence, high-speed applications. |
Which Cerebras model should you use?
-
Qwen 3 235B Instruct (2507): The strongest non-reasoning open model available. Choose when you need maximum intelligence at wafer-scale speed for production workloads, code generation, and agent-driven applications.
-
GLM 4.7: Best for coding and agentic workloads where you want frontier intelligence from an open model with extreme throughput (~1,000+ tokens/s).
-
Qwen 3 32B: The best reasoning model for real-time applications. Drop-in replacement for GPT-4.1 with higher intelligence, 16x speed, and a fraction of the cost.
-
GPT-OSS 120B: Best for agentic use cases requiring frontier-class intelligence at open-weight pricing with ~3,000 tokens/s inference speed.
-
Llama 3.3 70B: Good general-purpose model for academic work, Q&A, and coding at Cerebras speed.
-
Llama 3.1 8B: Ideal for ultra-fast, ultra-cheap simple tasks with ~2,200 tokens/s throughput.
Conclusion
Model descriptions compiled by Konstantinos Vassos